
It is a common practice in data science to split our data up into three separate datasets in order to perform machine learning (ML) on it. The majority of the data will be used to Train our ML models and then a portion of the remaining data will be used to Validate those models. The best of these models will then be applied to our Training data to evaluate its performance.
Graphical ML tools such as Azure Machine Learning often provide easily configurable drag-and-drop tools to split our data in this manner, but what happens if we are working on a custom solution, perhaps using something like SQL Server’s In-Database Machine Learning? In this blog post we’ll look at a couple of different T-SQL solutions to quickly split our data randomly into these datasets.
A common approach is to use 60-80% of our data for the Training set and to divide the remainder evenly between Validation and Testing. For our purposes we’ll split the difference and dedicate 70% of our data to training, leaving 15% to Validation and 15% to Testing.
For these examples, we’ll be looking at patient appointment data from our sample data warehouse. Firstly we want to maintain a record of which rows of data were in which dataset for the purposes of reproducibility and tracking data lineage, so we’ll add a column to our table to hold that information.
ALTER TABLE fact.Appointment ADD Dataset VARCHAR(10) NULL;
Next we’ll update that column randomly to one of Training, Validation, or Testing based on the percentages we specified above and run a quick GROUP BY query to look at the results.
-- Method #1 - Using the RAND() function
-- Definitely not the results we want!
DECLARE
@TrainingPercentage INT = 70,
@ValidationPercentage INT = 15,
@TestingPercentage INT = 15;
UPDATE
fact.Appointment
SET
Dataset = CASE
WHEN 100 * RAND() < @TrainingPercentage THEN 'Training'
WHEN 100 * RAND() < (@TrainingPercentage + @ValidationPercentage) THEN 'Validation'
ELSE 'Testing'
END;
SELECT
Dataset,
NumberOfRows = COUNT(*)
FROM
fact.Appointment
GROUP BY
Dataset
ORDER BY
Dataset;
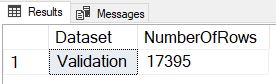
We see right away that this method failed horribly as all of the data was placed into the same dataset. This holds true no matter how many times we execute the code, and it happens because the RAND() function is only evaluated once for the whole query, and not individually for each row. To correct this we’ll instead use a method that Jeff Moden taught me at a SQL Saturday in Detroit several years ago – generating a NEWID() for each row, using the CHECKSUM() function to turn it into a random number, and then the % (modulus) function to turn it into a number between 0 and 99 inclusive.
-- Method #2 - Using the NEWID() function
-- Getting closer, but still not quite there
DECLARE
@TrainingPercentage INT = 70,
@ValidationPercentage INT = 15,
@TestingPercentage INT = 15;
UPDATE
fact.Appointment
SET
Dataset = CASE
WHEN ABS(CHECKSUM(NEWID())) % 100 < @TrainingPercentage THEN 'Training'
WHEN ABS(CHECKSUM(NEWID())) % 100 < (@TrainingPercentage + @ValidationPercentage) THEN 'Validation'
ELSE 'Testing'
END;
SELECT
Dataset,
NumberOfRows = COUNT(*)
FROM
fact.Appointment
GROUP BY
Dataset
ORDER BY
Dataset;
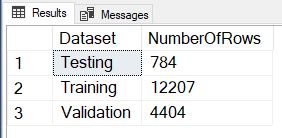
So this method failed too. Although we are getting the expected number of Training rows, the split between Validation and Testing is way off. What we find is that the NEWID() generated in the second line of the CASE statement is not the same value as in the first line, so we are getting an 85/15 split on the 30% of non-Training data instead of the expected 50/50. Let’s tweak the logic in that third line to fix the error.
-- Method #3 - Fixing the logical error
-- This works, but the size of the datasets varies slightly each run
DECLARE
@TrainingPercentage INT = 70,
@ValidationPercentage INT = 15,
@TestingPercentage INT = 15;
UPDATE
fact.Appointment
SET
Dataset = CASE
WHEN ABS(CHECKSUM(NEWID())) % 100 < @TrainingPercentage THEN 'Training'
WHEN ABS(CHECKSUM(NEWID())) % 100 < (@ValidationPercentage * 100 / (@ValidationPercentage + @TestingPercentage)) THEN 'Validation'
ELSE 'Testing'
END;
SELECT
Dataset,
NumberOfRows = COUNT(*)
FROM
fact.Appointment
GROUP BY
Dataset
ORDER BY
Dataset;
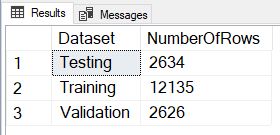
And success! The only thing we may notice is that if we execute this code multiple times, we get a slightly different number of rows in each dataset.
What if we have a requirement to have exactly the desired percentage of rows in each dataset, and to get that same exact percentage every time we execute? In this situation, we are going to generate a temp table that distributes the exact number of each dataset value randomly across all the rows, and then use that temp table to update the original table.
-- Method #4 - Consistent and exact
DECLARE
@RowCount INT,
@TrainingPercentage INT = 70,
@TrainingCount INT,
@ValidationPercentage INT = 15,
@ValidationCount INT,
@TestingPercentage INT = 15,
@TestingCount INT;
SELECT
@RowCount = COUNT(*)
FROM
fact.Appointment;
SET @TrainingCount = (FLOOR(@RowCount * @TrainingPercentage / 100.00) + 0.5);
SET @ValidationCount = (FLOOR(@RowCount * @ValidationPercentage / 100.00) + 0.5);
SET @TestingCount = @RowCount - (@TrainingCount + @ValidationCount);
SELECT
TrainingCount = @TrainingCount,
ValidationCount = @ValidationCount,
TestingCount = @TestingCount;
IF EXISTS (SELECT name FROM tempdb.sys.objects WHERE name LIKE '%Dataset%')
DROP TABLE #Dataset;
CREATE TABLE
#Dataset
(
AppointmentKey INT PRIMARY KEY,
Dataset VARCHAR(10) NULL
);
WITH SourceRows AS
(
SELECT
AppointmentKey,
RowNumber = ROW_NUMBER() OVER (ORDER BY CHECKSUM(NEWID()))
FROM
fact.Appointment
)
INSERT INTO
#Dataset
SELECT
AppointmentKey,
Dataset = CASE
WHEN RowNumber <= @TrainingCount THEN 'Training'
WHEN RowNumber <= (@TrainingCount + @ValidationCount) THEN 'Validation'
ELSE 'Testing'
END
FROM
SourceRows;
UPDATE
Appt
SET
Dataset = Dt.Dataset
FROM
fact.Appointment Appt
INNER JOIN
#Dataset Dt
ON Appt.AppointmentKey = Dt.AppointmentKey
SELECT
Dataset,
NumberOfRows = COUNT(*)
FROM
fact.Appointment
GROUP BY
Dataset
ORDER BY
Dataset;
SELECT TOP 25
AppointmentKey,
Dataset
FROM
fact.Appointment;
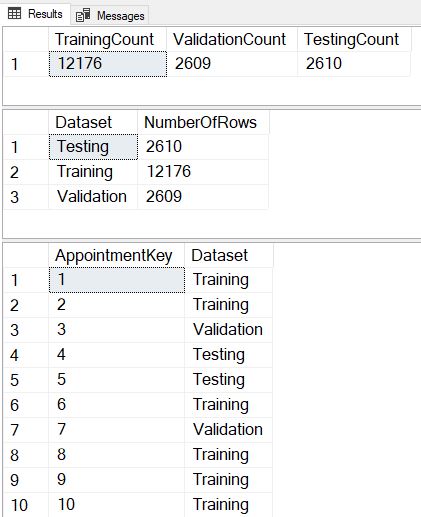
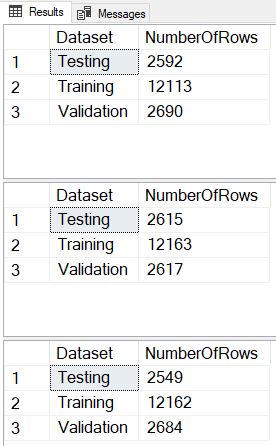
Now we see that we divide the rows in exactly the same proportions with each execution, and we’ve also included a SELECT TOP 25 so we can verify that each execution assigns different datasets to each row.
It’s possible that due to the JOIN this method might not be the best performing over extremely large datasets, so we also developed a brute-force method of splitting that performs three sequential updates that we could use instead in that specific circumstance.
-- Method #5 - The brute-force sequential method
DECLARE
@RowCount INT,
@TrainingPercentage INT = 70,
@TrainingCount INT,
@ValidationPercentage INT = 15,
@ValidationCount INT,
@TestingPercentage INT = 15,
@TestingCount INT;
SELECT
@RowCount = COUNT(*)
FROM
fact.Appointment;
SET @TrainingCount = (FLOOR(@RowCount * @TrainingPercentage / 100.00) + 0.5);
SET @ValidationCount = (FLOOR(@RowCount * @ValidationPercentage / 100.00) + 0.5);
SET @TestingCount = @RowCount - (@TrainingCount + @ValidationCount);
SELECT
TrainingCount = @TrainingCount,
ValidationCount = @ValidationCount,
TestingCount = @TestingCount;
UPDATE
fact.Appointment
SET
Dataset = NULL;
UPDATE
Appt
SET
Dataset = 'Training'
FROM
(
SELECT TOP (@TrainingCount)
*
FROM
fact.Appointment
ORDER BY
CHECKSUM(NEWID())
) Appt;
UPDATE
Appt
SET
Dataset = 'Validation'
FROM
(
SELECT TOP (@ValidationCount)
*
FROM
fact.Appointment
WHERE
Dataset IS NULL
ORDER BY
CHECKSUM(NEWID())
) Appt;
UPDATE
fact.Appointment
SET
Dataset = 'Testing'
WHERE
Dataset IS NULL;
SELECT
Dataset,
NumberOfRows = COUNT(*)
FROM
fact.Appointment
GROUP BY
Dataset
ORDER BY
Dataset;
SELECT TOP 25
AppointmentKey,
Dataset
FROM
fact.Appointment;
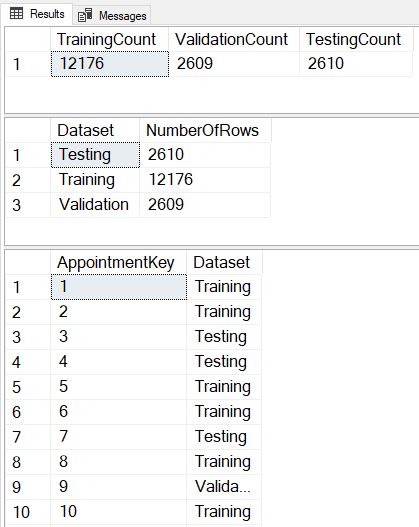
Hopefully you’ve enjoyed this look at randomly splitting our data in T-SQL. Please let me know in the comments what other methods you’ve used to tackle this problem!
Hi there, Chris…. good to “see” you again!
First, thank you for the article. It takes time to write such articles as well as to write, test, and explain the demo code. Anyone that takes such time is “Aces” in my book. Thank you also for the honorable mention in your good article.
As you pointed out, the random INT generator formula in the CASE operation is regenerated for each usage making it so that the second WHEN isn’t based on the same random INT as the first WHEN. That, of course and as you explained, causes the skew that you pointed out.
Your mathematical solution to correct the problem is great but, for UPDATEs, isn’t actually needed. We can avoid the complexity of having to realize such a formula by fixing the actual problem.
The actual problem is making it so we generate the random INT just once for every row. The really cool part is that the UPDATE clause in T-SQL has this functionality built in.
I didn’t see a link for your Appointment table so I used the following code to generate one. As usual for me, it’s a million row test table so that we can test for both functionality and performance with the same table generation code. You can reduce the number for the TOP for easy functionality testing and then use the number 1000000 (or more) for performance testing once the functionality testing has proven satisfactory.
–===== Create and populate the test table so that people don’t have to
— go looking for the test table you used.
— DROP TABLE IF EXISTS dbo.Appointment –Commented out for safety
;
SELECT TOP 1000000
AppointmentID = ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
,DataSet = CONVERT(CHAR(10),”) –Preseting to blank
,SimOtherCols = CONVERT(CHAR(100),’X’)
INTO dbo.Appointment
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
Shifting gears back to the problem at hand, if you check the documentation for the UPDATE statement at the following URL…
https://docs.microsoft.com/en-us/sql/t-sql/queries/update-transact-sql?view=sql-server-ver15
…you find the following is allowed in the SET clause…
@variable = expression
We can take advantage of that to “materialize” the random INT once for each and every row, which allows us to simplify everything as you had in the original #2 example but, this time it works as expected. (My apologies if this site causes the code to “wrap”.
–===== This works without complicated esoteric formulas in the CASE operator
DECLARE @TrainingPercentage INT = 70
,@ValidationPercentage INT = 15
,@TestingPercentage INT = 15
,@Rand1To100 INT –<=====<<<< Added this.
;
–===== This works without complicated esoteric formulas in the CASE operator.
— And, yes… it's supported in Books Online but the authors of Books Online make a silly claim tha
— it's not predictable and nothing could be further from the truth.
— Obviously, this isn't going to work for SELECTs. It only works for UPDATEs.
— @Rand1To100 is calculated for every row updated an then immediately used by the formula for Dataset.
UPDATE dbo.Appointment
SET @Rand1To100 = ABS(CHECKSUM(NEWID())%100)+1 –This fully materializes ONCE for EVERY row.
,Dataset = CASE
WHEN @Rand1To100 <= @TrainingPercentage THEN 'Training'
WHEN @Rand1To100 <= @TrainingPercentage + @ValidationPercentage THEN 'Validation'
ELSE 'Testing'
END;
–===== Show the counts to prove it works (with varying numbers, as you pointed out)
SELECT DataSet
,NumberOfRows = COUNT(*)
FROM dbo.Appointment
GROUP BY DataSet
;
Now, what about the "perfect" distribution you were able to get in your example #5? The answer is that we don't need any temp tables and we can actually pull this off in a single UPDATE. Here's the code. It uses the "trick" of using a CTE to generate the random value and then, using that random value from the CTE, we can update the CTE itself, which causes the underlying table to be updated. (I wish MS would document that feature a whole lot better!).
–===== This method still does the random assignment according to the following percentages
— but always creates a "perfect" distribution of the random values.
DECLARE @TrainingPercentage INT = 70
,@ValidationPercentage INT = 15
,@TestingPercentage INT = 15
;
WITH cteEnumerate AS
(–===== Assign a 1 to 100 number based on the modulus a random row number
— where the row number is totally unique in a serial fashion but
— randomly assigned for each row.
SELECT AppointmentID
,Dataset
,Rand1To100 = ROW_NUMBER() OVER (ORDER BY NEWID())%100+1
FROM dbo.Appointment
)
UPDATE cteEnumerate
SET DataSet = CASE
WHEN RandRowNum <= @TrainingPercentage THEN 'Training'
WHEN RandRowNum <= @TrainingPercentage + @ValidationPercentage THEN 'Validation'
ELSE 'Testing'
END
;
–===== Show the counts to prove it works (with varying numbers, as you pointed out)
SELECT DataSet
,NumberOfRows = COUNT(*)
FROM dbo.Appointment
GROUP BY DataSet
;
–===== Show that the results actually are random even though the percentage for
— each random is always perfect now.
SELECT TOP 100*
FROM dbo.Appointment
ORDER BY AppointmentID
;
Thank you again for the article and keep it up!
Ugh! The forum software doesn’t recognize leading white space and slammed all my nicely formatted/indented code to the left.
I really wish forum software were a bit more friendly when it comes to formatting code and other things that require leading white space. Nearly 3 decades in the making a so few forum/blog software gets it right. I had even converted the leading spaces to “non-breaking spaces” in Word before I posted.
What the hell is going on here? I know I posted a reply with a bunch of code in it. Where did it go??? Trying again…
Hi there, Chris…. good to “see” you again!
First, thank you for the article. It takes time to write such articles as well as to write, test, and explain the demo code. Anyone that takes such time is “Aces” in my book. Thank you also for the honorable mention in your good article.
As you pointed out, the random INT generator formula in the CASE operation is regenerated for each usage making it so that the second WHEN isn’t based on the same random INT as the first WHEN. That, of course and as you explained, causes the skew that you pointed out.
Your mathematical solution to correct the problem is great but, for UPDATEs, isn’t actually needed. We can avoid the complexity of having to realize such a formula by fixing the actual problem.
The actual problem is making it so we generate the random INT just once for every row. The really cool part is that the UPDATE clause in T-SQL has this functionality built in.
I didn’t see a link for your Appointment table so I used the following code to generate one. As usual for me, it’s a million row test table so that we can test for both functionality and performance with the same table generation code. You can reduce the number for the TOP for easy functionality testing and then use the number 1000000 (or more) for performance testing once the functionality testing has proven satisfactory.
–===== Create and populate the test table so that people don’t have to
— go looking for the test table you used.
— DROP TABLE IF EXISTS dbo.Appointment –Commented out for safety
;
SELECT TOP 1000000
AppointmentID = ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
,DataSet = CONVERT(CHAR(10),”) –Preseting to blank
,SimOtherCols = CONVERT(CHAR(100),’X’)
INTO dbo.Appointment
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
Shifting gears back to the problem at hand, if you check the documentation for the UPDATE statement at the following URL…
https://docs.microsoft.com/en-us/sql/t-sql/queries/update-transact-sql?view=sql-server-ver15
…you find the following is allowed in the SET clause…
@variable = expression
We can take advantage of that to “materialize” the random INT once for each and every row, which allows us to simplify everything as you had in the original #2 example but, this time it works as expected. (My apologies if this site causes the code to “wrap”.
–===== This works without complicated esoteric formulas in the CASE operator
DECLARE @TrainingPercentage INT = 70
,@ValidationPercentage INT = 15
,@TestingPercentage INT = 15
,@Rand1To100 INT –<=====<<<< Added this.
;
–===== This works without complicated esoteric formulas in the CASE operator.
— And, yes… it's supported in Books Online but the authors of Books Online make a silly claim tha
— it's not predictable and nothing could be further from the truth.
— Obviously, this isn't going to work for SELECTs. It only works for UPDATEs.
— @Rand1To100 is calculated for every row updated an then immediately used by the formula for Dataset.
UPDATE dbo.Appointment
SET @Rand1To100 = ABS(CHECKSUM(NEWID())%100)+1 –This fully materializes ONCE for EVERY row.
,Dataset = CASE
WHEN @Rand1To100 <= @TrainingPercentage THEN 'Training'
WHEN @Rand1To100 <= @TrainingPercentage + @ValidationPercentage THEN 'Validation'
ELSE 'Testing'
END;
–===== Show the counts to prove it works (with varying numbers, as you pointed out)
SELECT DataSet
,NumberOfRows = COUNT(*)
FROM dbo.Appointment
GROUP BY DataSet
;
Now, what about the "perfect" distribution you were able to get in your example #5? The answer is that we don't need any temp tables and we can actually pull this off in a single UPDATE. Here's the code. It uses the "trick" of using a CTE to generate the random value and then, using that random value from the CTE, we can update the CTE itself, which causes the underlying table to be updated. (I wish MS would document that feature a whole lot better!).
–===== This method still does the random assignment according to the following percentages
— but always creates a "perfect" distribution of the random values.
DECLARE @TrainingPercentage INT = 70
,@ValidationPercentage INT = 15
,@TestingPercentage INT = 15
;
WITH cteEnumerate AS
(–===== Assign a 1 to 100 number based on the modulus a random row number
— where the row number is totally unique in a serial fashion but
— randomly assigned for each row.
SELECT AppointmentID
,Dataset
,Rand1To100 = ROW_NUMBER() OVER (ORDER BY NEWID())%100+1
FROM dbo.Appointment
)
UPDATE cteEnumerate
SET DataSet = CASE
WHEN RandRowNum <= @TrainingPercentage THEN 'Training'
WHEN RandRowNum <= @TrainingPercentage + @ValidationPercentage THEN 'Validation'
ELSE 'Testing'
END
;
–===== Show the counts to prove it works (with varying numbers, as you pointed out)
SELECT DataSet
,NumberOfRows = COUNT(*)
FROM dbo.Appointment
GROUP BY DataSet
;
–===== Show that the results actually are random even though the percentage for
— each random is always perfect now.
SELECT TOP 100*
FROM dbo.Appointment
ORDER BY AppointmentID
;
Thank you again for the article and keep it up!
Ah… I see now. They don’t make the “awaiting moderation” note very obvious.